2 + 2*sin(pi)[1] 2R can be used as a calculator. Enter the following in the console.
2 + 2*sin(pi)[1] 2When we assign a value to a variable, it is better to use the assignment operator “<-” as below.
n <- 20
x <- 3^2There is a general preference among the R community to use “<-” (instead of “=”) for assignment for compatibility with (very) old versions of S-Plus.
Now you can click on environment (top right panel) to see the variables.
You will make lots of assignments, and <- can be annoying to type. You can save time with RStudio’s keyboard shortcut: Alt & - (the minus sign). Notice that RStudio automatically surrounds <- with spaces, which is a good code formatting practice.
| command | usage |
|---|---|
| rm(x) | remove variable x |
| rm(list = ls()) | remove all variables in the current environment |
| getwd() | list the current working directory |
| setwd(“/home/username/folder”) | change current working directory |
| cat(“\014”) | clears console (same as ctrl + l) |
| help(mean) or ?mean | Getting Help on function mean() |
| class() | find out data structure |
| str() | also find out data structure, can be more concise than class() |
The # symbol begins a comment. These will be used regularly to notate the action immediately below the comment. If a commented line is run in the R console, nothing will happen.
Keyboard shortcut:
| shortcut | function |
|---|---|
| [Alt] + [-] | generate ” <- ” |
| [Tab] | auto-fill |
| [Cmd/ctrl] + [enter] | execute code |
| [↑] | bring command history |
| [Cmd/Ctrl] + [↑] | bring command history with the same starting letters typed in console |
There are several types of structures (or variable types) in R.
The following defines a vector in R.
x <- c(3, -1, -3, 5, 2)
x[1] 3 -1 -3 5 2You can have a vector of strings.
s <- c("a", "b", "c", "d", "e")In R, the indexing starts at 1. Retrieve the 4th coordinate of s:
s[4][1] "d"Retrieve the first 3 coordinates of s
s[1:3][1] "a" "b" "c"Retrieve the 1st, 2nd, and 5th coordinates of s
s[c(1, 2, 5)][1] "a" "b" "e"Retrieve all coordinates but the 3rd
s[-3][1] "a" "b" "d" "e"length(s)[1] 5The function seq() is very handy in creating equally spaced numbers.
seq(from = 1, to = 10) [1] 1 2 3 4 5 6 7 8 9 10seq(from = 0, to = 1, by = 0.2)[1] 0.0 0.2 0.4 0.6 0.8 1.0y <- seq(1, 5)
y[1] 1 2 3 4 5And basic arithmetic on vectors is applied to every element of of the vector.
x * y[1] 3 -2 -9 20 10To create a df,
my_df <- data.frame(name = c("Amy", "Bob", "Cindy"),
Height = c(160, 170, 165))
my_df name Height
1 Amy 160
2 Bob 170
3 Cindy 165To retrieve the entry at the 3rd row and 2nd column.
my_df[3, 2][1] 165To retrieve the 2nd row of a df.
my_df[2, ] name Height
2 Bob 170Multiple ways to retrieve 1st col: df[,1], df[[1]], df$colname
my_df[, 1][1] "Amy" "Bob" "Cindy"my_df[[1]][1] "Amy" "Bob" "Cindy"my_df$name[1] "Amy" "Bob" "Cindy"In all the subselecting commands above, you can always replace the column index by the corresponding column name. For example, my_df[, 1] is the same as my_df[, “name”].
my_df[, 1][1] "Amy" "Bob" "Cindy"my_df[, "name"][1] "Amy" "Bob" "Cindy"The following is to subselect the first col and keep the data frame structure
my_df[1] name
1 Amy
2 Bob
3 CindyRecall that we can use class() to find out the data structure of any object.
class(my_df[, 1])[1] "character"class(my_df[1])[1] "data.frame"The function data() lists all data sets stored in R. “CO2” is a data frame that is stored in R.
Learn more about this data set.
?CO2The following commands are good for learning the data more.
head(CO2) # show the first 6 rows Plant Type Treatment conc uptake
1 Qn1 Quebec nonchilled 95 16.0
2 Qn1 Quebec nonchilled 175 30.4
3 Qn1 Quebec nonchilled 250 34.8
4 Qn1 Quebec nonchilled 350 37.2
5 Qn1 Quebec nonchilled 500 35.3
6 Qn1 Quebec nonchilled 675 39.2colnames(CO2) # get all the column names[1] "Plant" "Type" "Treatment" "conc" "uptake" dim(CO2) # find out the dimension (number of rows and number of columns)[1] 84 5nrow(CO2) # find out number of rows[1] 84We will be working with data frames a lot throughout this course.
CO2[CO2$uptake > 40, ] Plant Type Treatment conc uptake
11 Qn2 Quebec nonchilled 350 41.8
12 Qn2 Quebec nonchilled 500 40.6
13 Qn2 Quebec nonchilled 675 41.4
14 Qn2 Quebec nonchilled 1000 44.3
17 Qn3 Quebec nonchilled 250 40.3
18 Qn3 Quebec nonchilled 350 42.1
19 Qn3 Quebec nonchilled 500 42.9
20 Qn3 Quebec nonchilled 675 43.9
21 Qn3 Quebec nonchilled 1000 45.5
35 Qc2 Quebec chilled 1000 42.4
42 Qc3 Quebec chilled 1000 41.4The 2nd column of “CO2” is a factor. Factors are very useful for categorical variables.
class(CO2[, 2])[1] "factor"levels(CO2[, 2])[1] "Quebec" "Mississippi"table(CO2[, 2])
Quebec Mississippi
42 42 type2 <- factor(CO2[, 2], levels = c("Quebec", "Mississippi", "Others"))
table(type2)type2
Quebec Mississippi Others
42 42 0 Also see Section 27.3.3 of Hadley
A list can be thought of a vector that store different types of structures.
l <- list(a = 1:3,
b = "string",
c = data.frame(c1 = c(1, 2), c2 = c(2, 2)))[ extracts a sub-list. For example, l[1:2] is still a list.
l[1:2]$a
[1] 1 2 3
$b
[1] "string"[[ or $ extracts a single component from a list. For example, l[[1]] is a vector.
l[[1]][1] 1 2 3Good examples:
# x^2
# x * y
# x*y
# x / y
# x/y
# x + y
# x - y
# x[1:3] # no space around colon
# df[1, ]Read 4.1 and 4.2 of this book for more details.
The syntax for defining a new function in R is
# function_name <- function(parameter){content}To be filled
to be continued
In the near future, we will be using package “ggplot2” for its great data visualization ability. However, it is still very useful to know how to use base R to plot for its convenience and simplicity.
x <- c(2, 1, 3)
y <- c(100, 200, 300)
plot(x, y)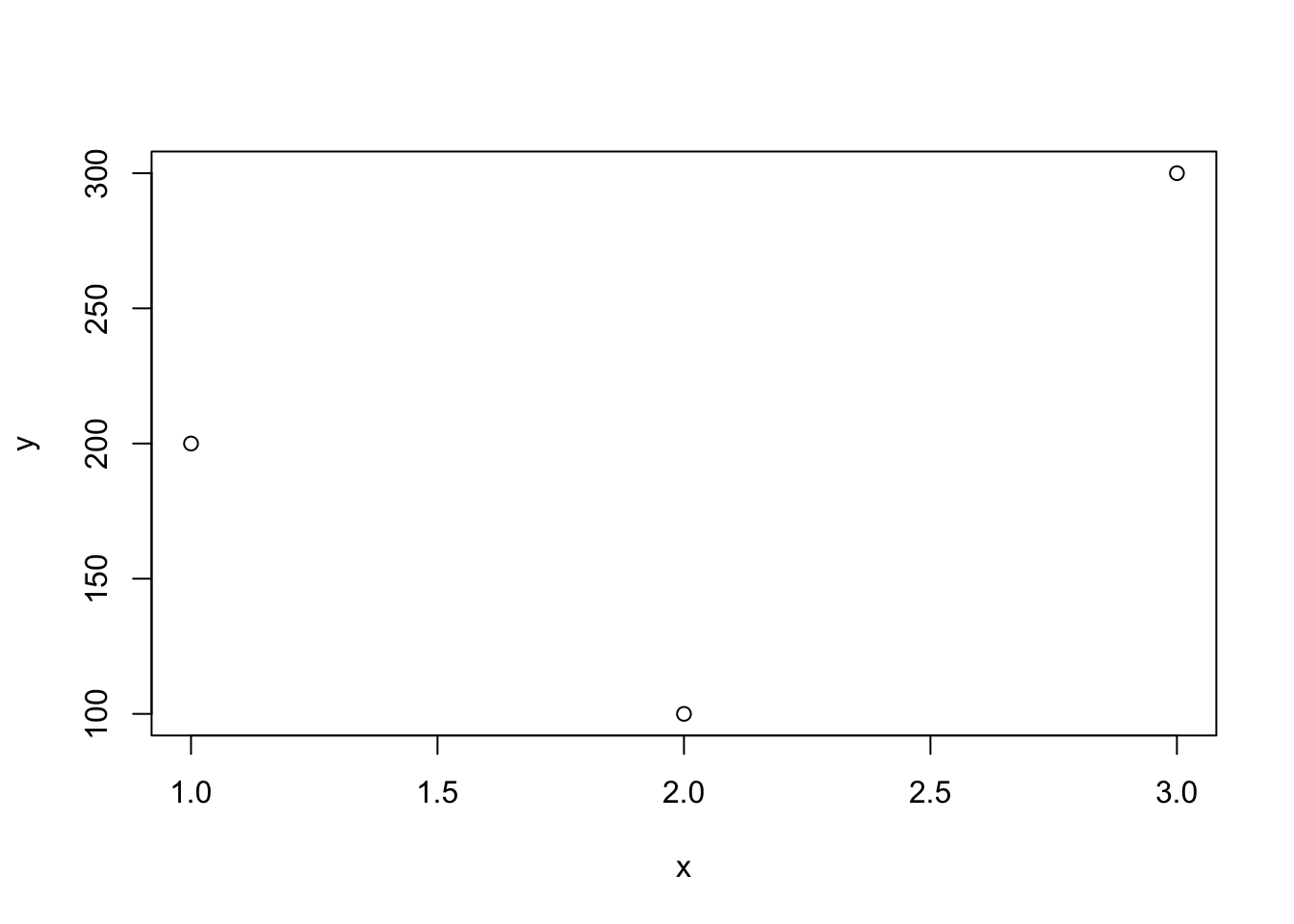
plot(x, y, type = "l", col = "red",
main = "Title", xlab = "x label", ylab = "y label")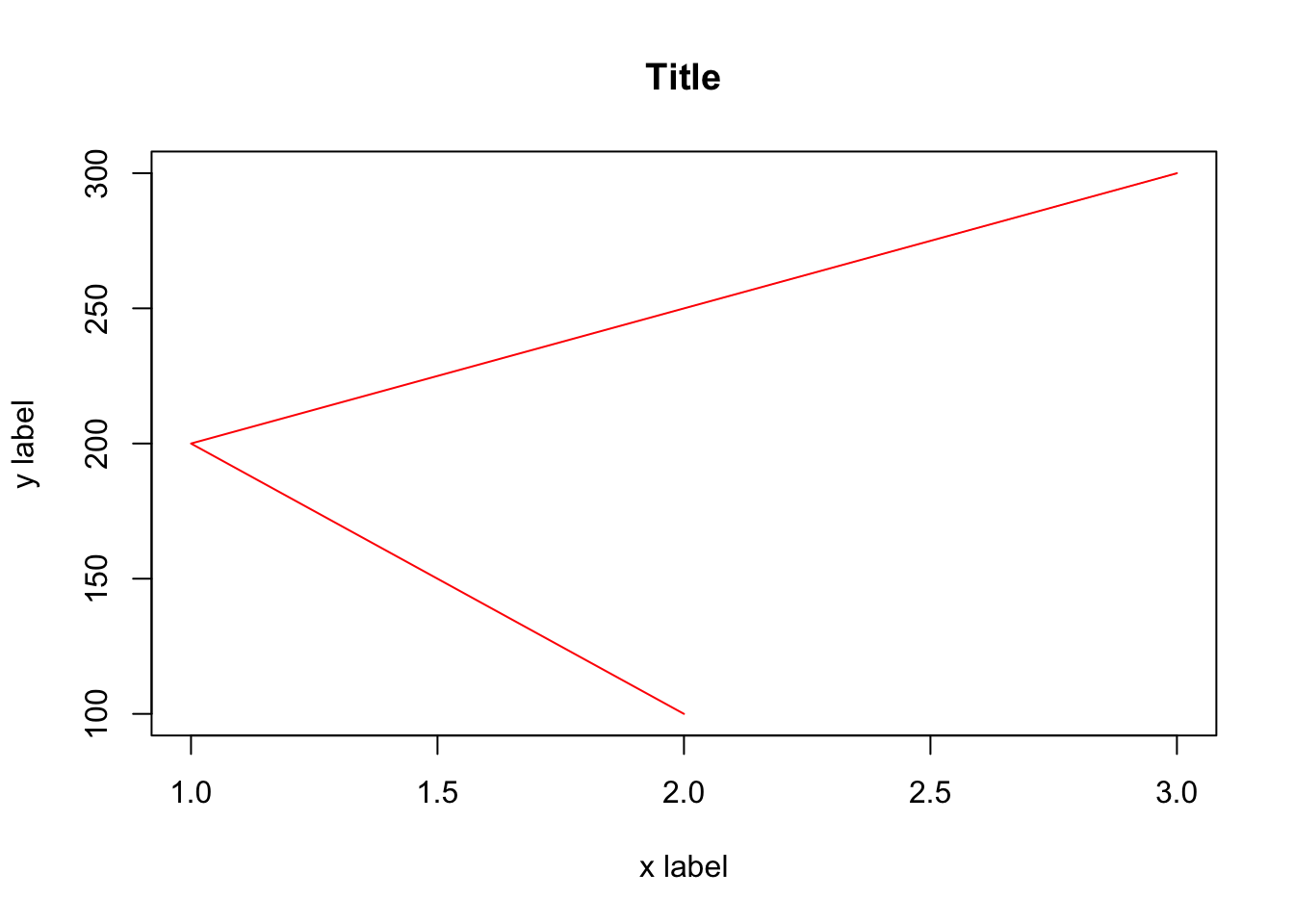
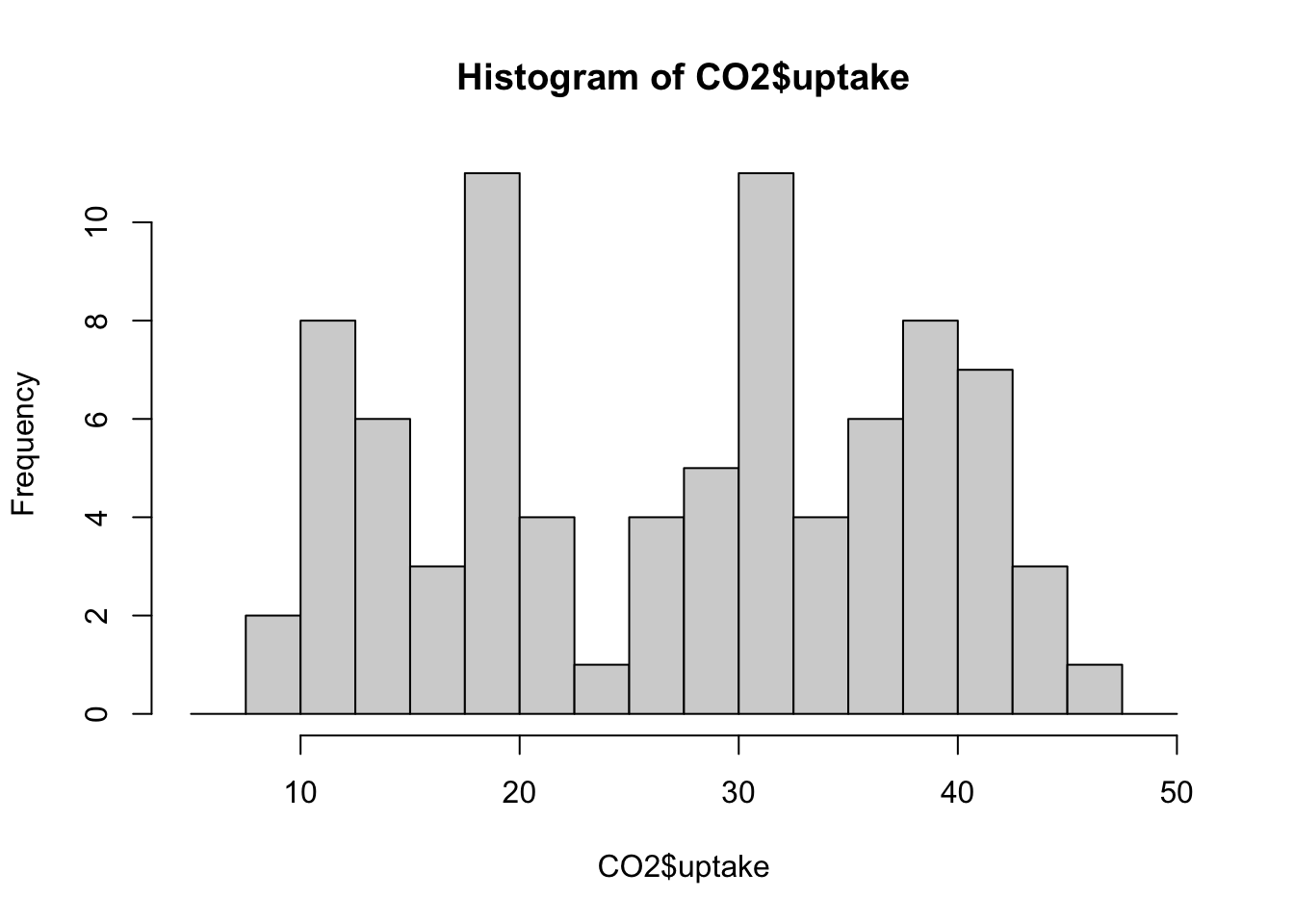
hist(CO2$uptake)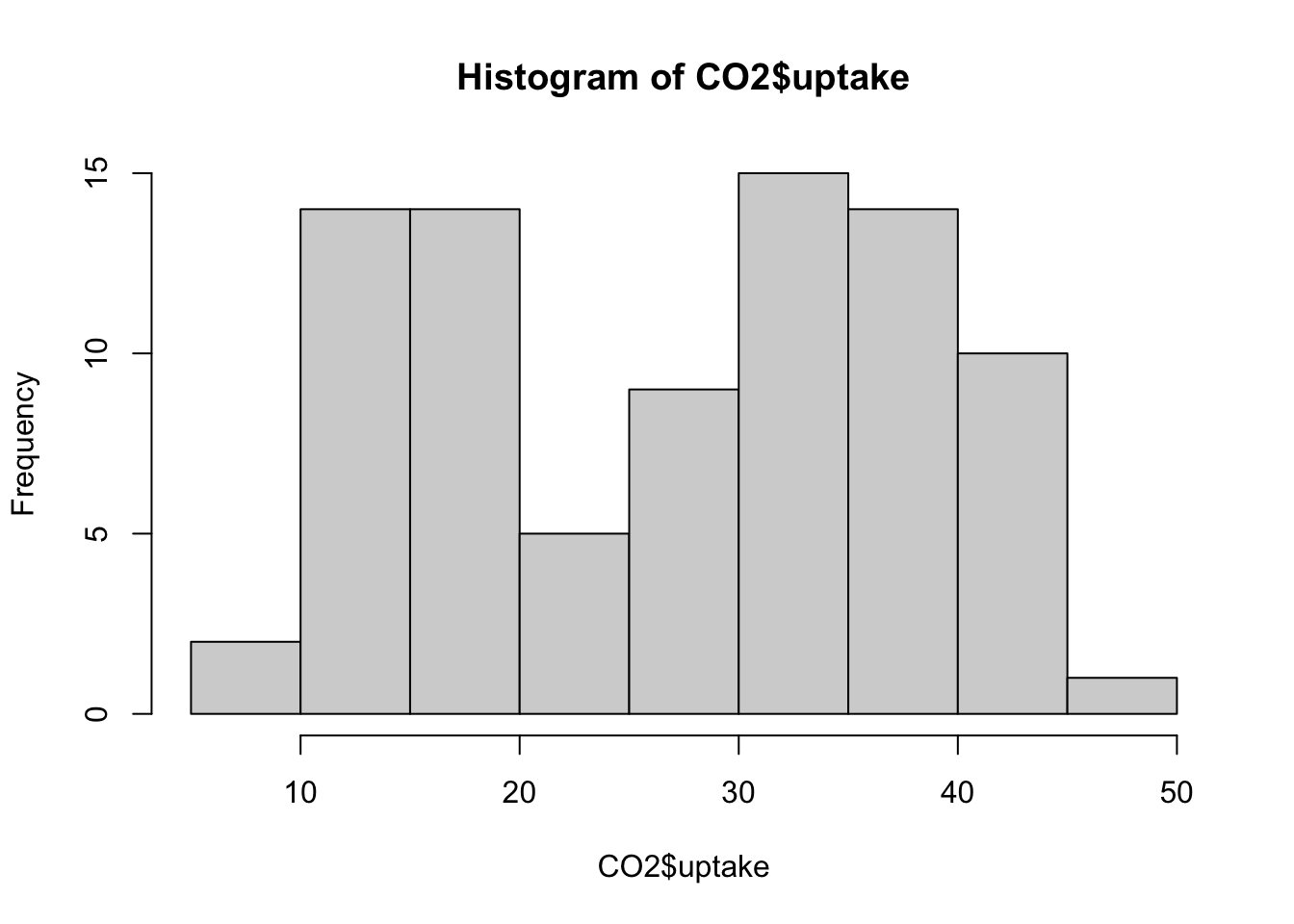
hist(CO2$uptake, breaks = seq(5, 50, 2.5))